Research
My research spans multiple topics in the area of formal methods and automated reasoning, with applications to artificial intelligence and controlling cyber-physical systems. I am particularly interested in solving search problems that are not in the complexity class NP and making reactive synthesis more practical.
Reactive Synthesis
Reactive synthesis is the process of automatically computing an implementation for a reactive system from its specification. While the problem is relatively old (with the first definition being from the 1960's), only recently, researchers started to look at how to solve this problem efficiently in practice. Together with several collaborators, I worked on making reactive synthesis more practical. The following list gives some examples of my results:
Generalized Rabin(1) Synthesis: Generalized reactivity(1) specifications, which are commonly abbreviated as GR(1) specifications, have a synthesis problem that is in the EXPTIME complexity class. Compared to the 2EXPTIME-completeless of reactive synthesis from full linear-time temporal logic, this is a relative low complexity class. However, the class of GR(1) specifications is strictly less expressive than full LTL and lacks, for example, support for stability properties. My NFM 2011 paper shows by how much the GR(1) specification class can be extended without losing the property that its synthesis problem is in EXPTIME.
Rüdiger Ehlers: Generalized Rabin(1) Synthesis with Applications to Robust System Synthesis. 3rd NASA Formal Methods Symposium (NFM 2011)
Click here to download the author-archived version of the paper. Copyright by Springer Verlag. The original publication is available at www.springerlink.com
There are some author's notes available for this paper.Estimator-based Reactive Synthesis: In many synthesis problems for cyber-physical system controllers, a controller must be able to deal with incomplete information. While for many specification logics such as linear temporal logic (LTL), adding incomplete information does not increase the complexity of the synthesis problem, Ufuk Topcu and I showed that for GR(1) specifications, the complexity of the synthesis problem increases from singly-exponential to doubly-exponential time in this case. To still make use of the efficiency of GR(1) synthesis under incomplete information, we developed a two-step synthesis approach that retains the EXPTIME-completeness of GR(1) synthesis. In the first step, we compute an estimator for the state of the real world, which is then used as a plant model in the later synthesis step. While the approach requires an additional estimator specification to be applicable, it effectively reduces the complexity of the synthesis problem and makes synthesis more practical, as we showed in a case study.
Rüdiger Ehlers and Ufuk Topcu: Estimator-based Reactive Synthesis Under Incomplete Information. 18th International Conference on Hybrid Systems: Computation and Control (HSCC 2015)
This is the authors' version of the work. It is posted here for your personal use. Not for redistribution.
The 2EXPTIME-hardness proof for GR(1) synthesis under incomplete information can be found in the appendix of the paper.Synthesizing Small Finite-State Implementations: Most reactive synthesis approaches reduce the synthesis problem to finding a winning strategy in a game. The winning strategy can then be interpreted as a finite-state machine that implements the specification from which the game was built. One typically strives for smaller finite-state machines in this context, as they can be implemented in hardware with fewer gates, and are shorter when implemented in software. I analyzed the complexity of finding sparse winning strategies in games, i.e., those that minimize the number of positions reachable in the game and hence minimize the number of states in the finite-state machine constructed from a strategy. It turns out that even approximating the size of such a strategy by any constant factor is NP-hard. For some game types, even stronger hardness results were shown.
Rüdiger Ehlers: Small Witnesses, Accepting Lassos and Winning Strategies in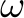 -automata and Games. AVACS Technical Report No. 80, also available as ArXiV/CoRR 1108.0315 (2011)
-automata and Games. AVACS Technical Report No. 80, also available as ArXiV/CoRR 1108.0315 (2011)
Combining Formal Methods and Artificial Intelligence
While formal methods give provable guarantees for the quality of an implementation, synthesis often lacks the scalability needed for complex practical applications. Methods from artificial intelligence, such as artificial neural network learning and reinforcement learning using function approximation can mitigate scalability problems, but do not offer the correct-by-construction guarantees that formal methods offer. Combining techniques from artificial intelligence and formal methods promises to get the best of both worlds.
Formal Verification of Feed-Forward Neural Networks: Artificial Neural Networks have been shown to be useful tools for classification and control purposes. However, they are notoriously difficult to analyze, which makes their application in safety-critical applications problematic. Modern neural network architectures often use activation functions that are piecewise affine. These allow casting verification problems over neural networks as satisfiability modulo theory (SMT) problems, which have been shown to be difficult to solve for modern SMT solvers. To mitigate this problem, I developed an approach to compute a linear over-approximation of the overall network behavior, whose addition as (redundant) constraints make neural network verification problems much more amenable to getting solved with mixed-integer linear programming (MILP) or SMT solvers. The new approach can be used, for instance, to verify the robustness of image recognition neural networks against error models that resemble image noise in a more realistic way than as studied in previous works on neural network verification.
A preprint of the paper is available on ArXiV/CoRR. Copyright by Springer Verlag. The final publication is available at link.springer.com.
Note that the preprint has exactly the same content as the published version.Reinforcement Learning under temporal logic constraints: Reinforcement learning allows to learn good control policies for Markov decision processes (MDPs) at runtime under an a-priori unknown cost/reward function. Together with Min Wen and Ufuk Topcu, I tackled the problem of performing reinforcement learning under an arbitrary LTL specification. The problem could relatively easily be solved by composing the MDP with a maximally permissive strategy for the specification, but in general, LTL specifications do not permit maximally permissive strategies. To still allow reinforcement learning in this setting, we defined the notion of a permissive strategy that is conceptually in between a positional strategy in a parity game built from the specification and the maximally permissive strategy for the safety hull of the specification.
Min Wen, Rüdiger Ehlers, and Ufuk Topcu: Correct-by-synthesis Reinforcement Learning with Temporal Logic Constraints. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2015)
The publisher's version of the paper can be obtained from IEEE Xplore here.
In case you do not have access to the paper on IEEE Xplore, the pre-print (before review) can be obtained from ArXiV/CoRR.